by Tim C. Lueth, SG-Lib Toolbox: SolidGeometry 5.6 - Video/Audio/PDF
Introduced first in SolidGeometry 4.9, Creation date: 2020-03-28, Last change: 2025-09-14
See Also: audiotrim
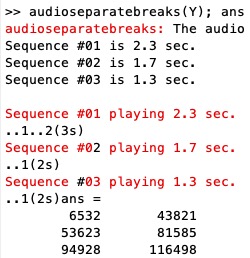
[Voice,VLen]=audioseparatebreaks(y,[FS,damp,brkdur,minvoic])
y: | Audio Signal | |
FS: | Sample Rate; default is 16000 | |
damp: | damping for break detection; linear = ; defalt 0.01 = -40dB | |
brkdur: | minimum break durance default is 0.3 seconds | |
minvoic: | minimal voice length; default is 1 second |
Voice: | List of [start and end] samples for the voice segments | |
VLen: | length of the individual segments |
[Y,FS]=audioreadTL('/Users/lueth/Desktop/Ohne Titel.mp4'); [Y,FS]=audioresample(Y,FS,16000); FS
soundTL(Y,FS)
audioseparatebreaks(Y);